普通のPC+ノー環境構築でAI画像生成を遊ぶ

AIによる画像生成「Stable Diffusion」が話題なので、さっそく遊んでみましたのですが、これが結構面白いです。おもしろ画像を生成してくれるキーワードを大喜利のような感覚で探して楽しめます。例をいくつか挙げると
普通のPC+ノー環境構築でAI画像生成を遊ぶ Read More »
AIによる画像生成「Stable Diffusion」が話題なので、さっそく遊んでみましたのですが、これが結構面白いです。おもしろ画像を生成してくれるキーワードを大喜利のような感覚で探して楽しめます。例をいくつか挙げると
普通のPC+ノー環境構築でAI画像生成を遊ぶ Read More »
拙作のタイ語辞書アプリ「ごったい」のアップデート時の審査で、「不適切な広告に関するポリシー違反」ということでリジェクト(非承認)を喰らってしまいました。同様にリジェクトされてしまった人の参考になるかと思い、対応とあきらめの歴史を記事にしておこうと思います。
Google Play審査リジェクト「不適切な広告」に対応する Read More »

Google Playで公開済みのAndroidアプリのアップデートをリリースしようしたら、審査でリジェクト(非承認)されてしまいました。なんとか対応できて無事公開に漕ぎつけることができたので、その方法を記事にしておきます。
Google Play審査リジェクト「ユーザー作成コンテンツ」に対応する Read More »
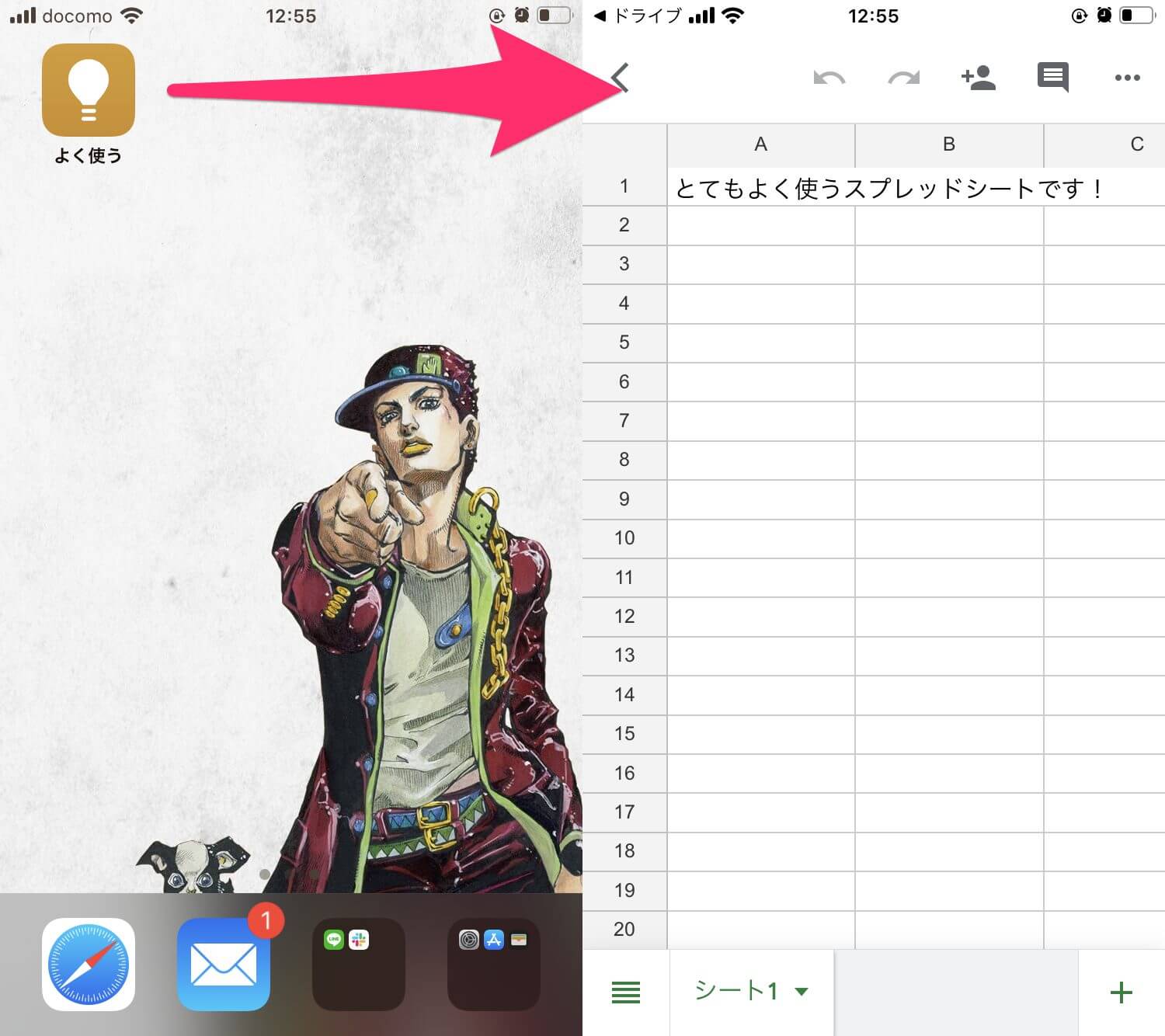
Googleのスプレッドシートの中でよく使うシートをiPhoneのホーム画面に追加する方法を紹介します。
iPhoneのホーム画面に特定のスプレッドシートを追加する Read More »
相変わらず愛しいVoice Kit V2です。
なおOpen JTalkではなく、前々回のGoogleあるいは前回のAmazonを試してみたい人は以下のリンクからどうぞ。
ラズベリーパイに日本語で喋らせる[その1]Google Cloud Text-To-Speech
ラズベリーパイに日本語で喋らせる[その2]Amazon Polly
Google、Amazonともに有料APIです(無料枠はありますが)。その点Open JTalkは完全無料かつオフラインで利用できるというメリットがありますので、用途によっては選択肢のひとつになると思います。というわけで試してみましょう。
私はRaspbianOSでやってますが、Linux系でスピーカー付いてりゃ何でもいいと思います。
とりあえずdebian系の方はいつもどおりaptでインストールします。
$ sudo apt install open-jtalk open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001
3つのパッケージをインストールします。open-jtalk本体とmecab辞書、それに音声の3つです。open_jtalkコマンド実行時に辞書ディレクトリと音声モデルを指定する必要があります。基本的な書式は次のような感じ。
$ open_jtalk -x <辞書ディレクトリ> -m <音声ファイル> -ow <出力するwavファイル>
読み上げるテキストは標準入力かファイル名を指定します。先程インストールした辞書はRaspbianOSの場合は /var/lib/mecab/dic/open-jtalk/naist-jdic/ に、音声モデルは /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice にインストールされています。
実際に何か読み上げてみます。
$ echo "こんにちわ、私は金正恩です" | open_jtalk -x /var/lib/mecab/dic/open-jtalk/naist-jdic/ -m /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice -ow test.wav $ aplay test.wav
上手く読み上げできました? 標準の男性音声で再生されます。ちなみにaplayが入ってない環境なら、なんとかして作成したwavを再生してください。
ではPythonから合成・再生ができるようにしてみます。python用のライブラリがあるわけではないので、直接コマンドを叩く感じになります。
#!/usr/bin/env python3
import sys
import subprocess
DICT_PATH='/var/lib/mecab/dic/open-jtalk/naist-jdic/'
VOICE_PATH='/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice'
while True:
print('何か入力してエンターキーを押してね(CTRL+Cで終了)')
text = input()
with open('speech.txt', 'w') as f:
f.write(text)
subprocess.run(['open_jtalk', '-x', DICT_PATH, '-m', VOICE_PATH, '-ow', 'speech.wav', 'speech.txt'])
subprocess.run(['aplay', 'speech.wav'])
色々喋らせてみたんですが、音声合成の処理時間が結構かかってますね・・・。「こんにちわ」でも1秒ぐらいかかってます。非力なラズパイZeroだからかなあ・・・?これならGoogleやAmazonのオンラインAPIと大差無い気もします。
音響モデルを変更することで音声を変えることができます。このサイトが詳しいみたい。
MMDAgentのモデルが比較的高精度なモデルのような気がしますので、これだけ試しておきましょう。以下URLからファイルをダウンロードします。
MMDAgent_Example-1.8.zipというファイルをダウンロードします。解凍したらVoiceディレクトリの中にmeiとtakumiという音響モデルがありますが、これらが日本語音響モデルです。感情毎にモデルが別れているみたいですね。
モデルを先程のpythonで試してみる場合は、VOICE_PATHの値を適当に変更してください。
Open JTalkで使用できる音響モデルは正直言ってGoogleやAmazonのものと比べると見劣り(聞き劣りというべき?)しますね・・・。やはりGoogleやAmazonは偉大ということか・・・。外部APIを叩いてもサクッと返ってきますし、無料枠も太っ腹(特にGoogleは)なので、あえてOpen JTalkを使用する必要はないかな。地味にSSMLも役立ちそうな気もしますし。
そんな感じです。
ラズベリーパイに日本語で喋らせる[その3]Open JTalk Read More »